
Szerző: Szenek Zoltán
A nyers és zajos szenzoradatoktól a skálázható, ultra-nagy felbontású ROI alapú döntéstámogatásig
A mezőgazdaság ma már egyáltalán nem hasonlít a korábban megismert, sokszor romantizált önmagára. Az ASZ protokoll (Ahogy Szoktuk) egy fenntarthatatlan és letűnt kor emléke kell, hogy legyen minden, a közeljövőben is működni szándékozó gazdaság életében. Nincs többé korlátlanul szórható műtrágya, vetőmag és növényvédőszer, felesleges munkaműveletek; van helyette különféle adatsilókból történő adatbeszerzés, adatfeldolgozás, helyspecifikusan tervezett kijuttatás, megvalósulási visszamérés, cella szintű gazdaság optimalizálás. A mezőgazdaság jövője, az egyes gazdaságok jövedelmezősége ma már vastagon a térbeli adattudomány (spatial data science) hatáskörébe tartozik. Itt dől el, hogy ki marad fenn már az elkövetkező pár éven belül. És nem, nem az egyes támogatásokon és azok mértékén áll vagy bukik.
A duplán skálázhatóság a kulcsa itt is mindennek
Bármilyen iparágról is legyen szó, ha tervezési- és megvalósíthatósági oldalról sem skálázható a működése, akkor az fenntartható módon egész egyszerűen nem fog működni. Nézzük ezt meg a szántóföldi mezőgazdaság példáján. Adott egy gép oldalról precíziósan működni képes gazdaság. Akkor „már csak annyi hiányzik”, hogy valaki ezeket a gépeket egy előre meghatározott szempontrendszer szerint, helyspecifikusan súlyozott anyagkijuttatás révén optimalizáltan üzemeltetni tudja. Ehhez pedig adatok kellenek. Strukturálatlan, nyers, hibákkal (outlier-ekkel) tele adathalmazok különféle bemeneti formákban (pont, poligon, multipoligon). Ezekből szakszerű, tudományos igényű adatfeldolgozás nélkül csak saját magunk felé fordított fegyver lesz, mert sokkal nagyobb kár származhat belőle mint a korábban megszokott konvencionális kezelések esetén. Ehhez pedig már kevés egy átlagos agronómus vagy térinformatikus, ide már specializált szakember szükséges. Tehát garantáltan mondhatom, hogy a legtöbb esetben kilépünk a házon belül megoldjuk módszerből és megérkezünk a külsős szakértőkhöz. Ezek a külsős szakértők mint mi is, megbízást kapnak egyszerre több gazdaság precíziós tervezésére, működésük optimalizálására. Azonban a munkaműveletek olyan összetettek és annyi számítást kell lefuttatni, hogy szóba sem jöhet, hogy manuálisan végig kattintgassunk minden táblát. Ezzel belépünk a térinformatikai szoftverekbe beépülő fejlesztői környezetbe, ahol már eddig is automatizált pipeline-okat építettünk fel. Ezzel kizártuk az emberi hibát, de szigorúan továbbra is emberi felügyelet mellett működő, skálázható tervezőrendszert hoztunk létre.
Kérdés, hogy erre miért van szükség, hiszen bőven léteznek már kész, felhasználóbarátan működő dedikált webgis rendszerek?! Léteznek persze, de azok teljes mértékben alkalmatlanok okszerűen és helysepcifikuan tervezett kijuttatás tervezésre és gazdaság optimalizálási döntések előkészítésére, megtételére.
A következő szint, hogy a gazdaság működése is skálázhatóan történjen. Ez már a megvalósulási szakasz, ahol a gondosan megtervezett kijuttatási térképeink végrehajtását visszamérjük, kiszámítjuk cella szinten a relatív hozam válaszát az adott mennyiségű műtrágya-, vetőmag-, növényvédőszer adagokra és a következő szezonban már ezekre épülő, még tovább optimalizált kijuttatásokat tudunk tervezni. Pontosan ez a szemléletmód vezet el a fenntartható, skálázható termékpálya modellhez.
Persze lehet itt azzal jönni, hogy légköri- és talajszintű aszály lép fel egyre gyakrabban és egyre súlyosabb formában, akkor minek ez az egész „túltervezés”, úgyis bukó minden. Ökonómiai értelemben a lehető legveszélyesebb gondolkodásforma ez, mert csak abba kellene belegondolni, hogy akkor mekkora a bukó, ha egy dózisban ment ki minden, mindenféle gondolkodás, tervezés nélkül, na és akkor vajon mennyi év lehet még hátra a csődig?
Az adat az új arany, de milyen eszközökkel bányásszuk ki és hogyan dolgozzuk fel?
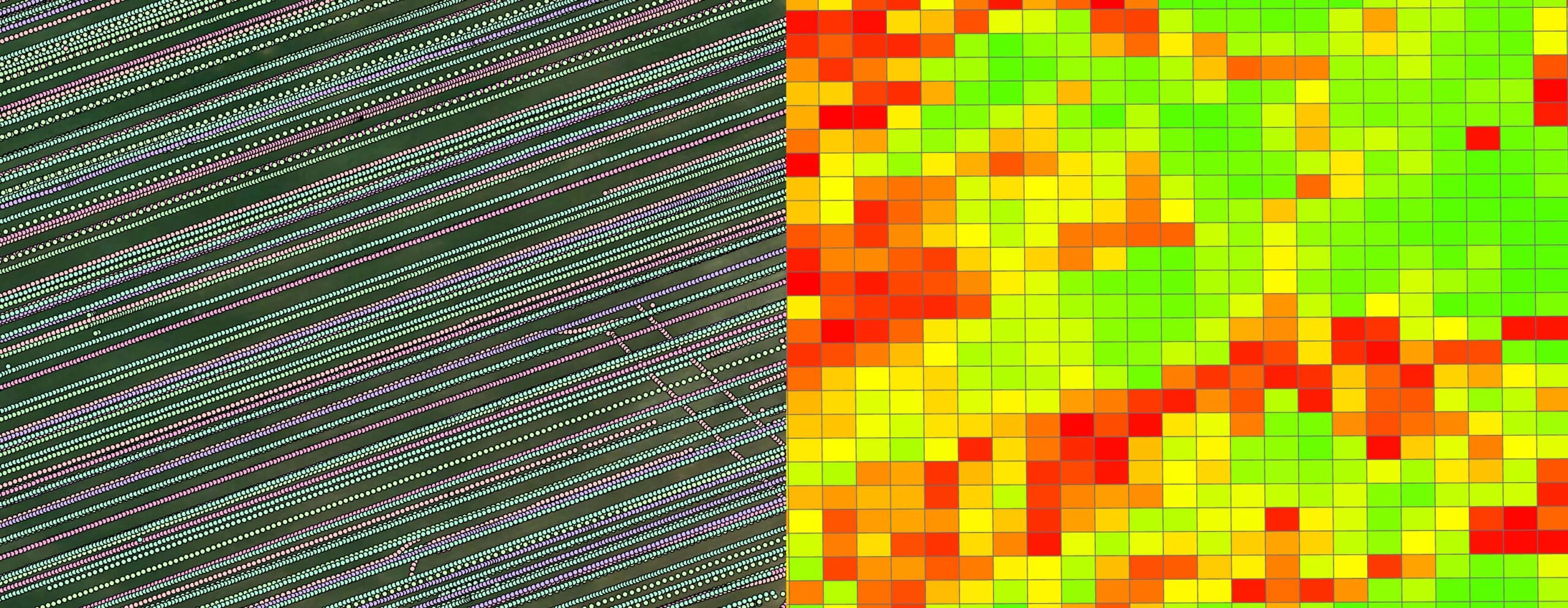
A mezőgazdaságban a helyspecifikus (a precíziós általános, tágabb értelmű, nem helyoptimalizált) tervezés legfontosabb, legpontosabb és legnehezebben hozzáférhető építőköve a hozamadat, ami a kombájnokból különféle formákban érkezhet. Lehet pontszerű és sávos, (multi)poligonokba rendezett is. A nyers, érintetlen hozamadat legtöbbször a kombájn monitorjából letölthető pontadat. Ha csak felhőből érhető el vagy multipoligon alakot ölt, akkor gyakorlatilag biztosan kijelenthető, hogy az már nem a nyers adat, hanem a gyártó rendszerében ismeretlen munkaműveletekkel feldolgozott adat. Azonban még ilyen formában is sokkal alkalmasabb kijuttatástervezésre, mint a műholdas vagy drónos NDVI alapú tervezés.

A tervezéshez mi platformfüggetlen tervezőszoftvereket használunk. Leginkább az ArcGIS Pro-t, oktatásokhoz a QGIS-t, adatkonvertáláshoz az AgLeader SMS-t, adatelemezésekhez a Visual Studio Code-ot, de már egyre inkább a Pycharm felé mozdulunk el. Ebből is látszik, hogy a munkánkhoz kevés egy térinformatikai alapszoftver, így pythonban programozott pipeline-okat építünk fel munkánk során, amiket minden beérkező új adat estén tovább finomítunk.
Adaptív adattisztítás és dinamikus outlier-szűrés (IQR)
A kombájnnal együtt mozgó ütközőlapos vagy optikai szenzorok a beérkező anyagáram tekintetében mérik a kalibráció során megadott értékek függvényében az alapvető adatokat. Azonban ezek a mikrodomborzat, a haladási sebesség, és a fordulók miatt zajjal terheltek, ezért létfontosságú az outlierek kezelése. A gyakorlatban sokszor alkalmazott, statikus küszöbértékeken (hard-coded limiteken) alapuló szűrés itt azonnal elvérzik, mivel a rendszer dinamikáját és a lokális környezet változásait teljesen figyelmen kívül hagyja. Fix határértékekkel vagy értékes valós adatokat veszítünk el, vagy rejtett hibákat engedünk át az elemzés további szakaszaiba.
Ezen probléma áthidalására a szűréshez egy saját fejlesztésű, adaptív IQR (Interkvartilis) algoritmust implementáltunk.
A hagyományos, merev határértékek helyett a kódunk dinamikusan vizsgálja a táblaszintű adathalmaz értékeinek eloszlását. Az eljárás során első lépésként meghatározzuk a rendszer legstabilabb magját, vagyis az adattömeg központi 50%-os eloszlását (az első, Q1 és a harmadik, Q3 kvartilis közötti tartományt). Ez adja meg a dinamikus alapértékeket (IQR = Q3 – Q1). A módszerünk adaptív működése abban rejlik, hogy az alsó és felső vágási korlátokat nem egy univerzális konstanssal definiáljuk, hanem azokat a középső tartomány varianciájához (a sűrűségi profilhoz) kötjük. Ez az adaptív megközelítés két szinten tisztítja az adatbázist:
- A globális zaj szűrése: levágja a matematikai értelemben vett, nyilvánvalóan extrém szélsőértékeket, melyeket a mikrodomborzat, a haladási sebesség változásai, és a fordulók generálnak.
- A lokális anomáliák azonosítása: A sávok dinamikus szűkítésével képes azonosítani és eltávolítani azokat a „köztes” hibás adatpontokat is, amelyek ugyan normálisnak (átlagosnak) tűnnének, de a saját lokális adatkörnyezetük (táblaszintű) varianciájához viszonyítva valójában statisztikai zajt jelentenek.
A kódunk úgy tisztítja meg a gyakran több millió pontos adathalmazokat egy projekten belül, hogy a valós, fizikai extremitásokat megőrzi, de az outlier-eket maradéktalanul izolálja, megteremtve a tökéletes alapot a cellaszintű, predikciós modellekhez.
A raszteres diffúzió kiküszöbölése és GPU-gyorsított vektoros interpoláció
A hagyományos térinformatikai szoftverek (standard GIS) beépített interpolációs eszközei (geoprocessing tool-jai) szinte kivétel nélkül raszteres megközelítést alkalmaznak. Amikor egy ilyen szoftverre rászabadítunk több millió adatpontot, a beépített matematikai modellek (pl.: az IDW Inverse Distance Weighting) elkenik az értékeket a térben. A raszteres algoritmus úgy működik, mint egy digitális elmosás (a Photoshopban blur). Ha az algoritmus talál egy lokális, éles anomáliát (például egy valósnak számított hozamkilengést), ahelyett, hogy megőrizné annak éles fizikai határvonalait, a környező üres pixelekre is kiszámol egy hibás, fokozatos átmenetet. Ez a térbeli diffúzió elmossa az adatok statisztikai integritását és hibás relatív teljesítmény adatok meghatározásához vezetnek.
Ennek kivédésére egy tisztán vektor alapú eljárást fejlesztettünk ki, melynek eredményeként a teljes tervezési folyamatban sehol nem lépünk ki a raszteres térbe.
A térbeli folytonosság megteremtésére egy k-NN (k-Nearest Neighbors, k=12) alapú, inverz távolságméréssel súlyozott (IDW) vektoros interpolációt alkalmaztunk. A kódunk minden egyes pontadatot megmér és a hozzá legközelebb eső 12 másik adatpont távolság alapú súlyozott átlagolása útján egyetlen új kimeneti adatpontot képez, így a bemeneti pontfelhőből 10*10 méteres rácsközéppontonként egyetlen értékkel szállnak ki. Az interpoláció a legszámításigényesebb munkafolyamat, de egyúttal elengedhetetlen is, hogy a folytonossági hibák megszűnjenek. Mind a reszteres mind a vektoros megközelítésnek alapesetben egy közös hátránya van, a számítási igényük brutális. Ahhoz, hogy az architektúra ipari léptékben (enterprise-scale) is azonnal bevethető legyen, a kód futását egy teljes gazdaság esetében órákról percekre rövidítettük az alábbi módszerekkel:
- Térbeli indexelés: A lineáris távolságkeresés helyett bevetettük a cKDTree (k-Dimensional Tree) algoritmust. Ez a struktúra az adatpontokat egy bináris fába rendezi, így a legközelebbi szomszédok keresése másodpercek töredéke alatt lefut.
- Hardveres gyorsítás: A párhuzamosítható mátrixműveleteket GPU-alapú számítási gyorsítással támogattuk meg.
Az optimalizált pipeline lehetővé tette, hogy az évek során felhalmozott heterogén hozamadat halmazokat egyetlen, 10*10 méteres rácshálóba, multidimenzionális adatkockába (data cube) integráljuk.
Kockázati profilozás és döntéstámogatás multidimenzionális adatkocka szinten
Több éves hozamadatsor megléte esetén, az ezekkel a módszerekkel tisztított, interpolált adatok adják magukat, hogy átlagoljuk ki őket, így egy multitemporális, az adott tábla teljesítményének sokkal inkább megfelelő képet láthatunk. Leggyakrabban és legelterjedtebb formában ez valóban így is történik. Azonban van ennek egy óriási hibája. Ha egy térbeli cella teljesítménye az egyik évben 100%, a másik évben pedig 0%, annak az átlaga 50% lesz. Egy másik cella, ami minden évben stabilan 50%-ot hoz, statisztikailag ugyanúgy fog kinézni a térképen. A valóságban azonban ezen két területegység kockázati profilja és környezeti stressztűrő képessége nagymértékben eltér egymástól. Ezért egy radikálisan új módszer bevezetése szükséges, ami statisztikailag sokkal pontosabban mutatja meg minden cella valódi, több éves teljesítményét.
A rejtett mintázatok feltárására ezért egy statisztikai kvadráns-analízisre épülő teljesítménystabilitási mátrixot fejlesztettünk ki.
A modellünkkel egy egyedülálló 7 éves hozamadatsorral rendelkező gazdaságban a normalizált multidimenzionális adatkocka minden egyes cellájára két kritikus, egymástól független változót számoltunk ki:
- Relatív Átlagteljesítmény (Középérték): Minden évet önmagához normalizáltunk, kiküszöbölve az évjárathatást. Ez a mutató azt jelzi, hogy az adott cella az adott tábla átlagához képest jellemzően milyen teljesítményt mutat.
- Interannuális Variancia (Volatilitás / CV – Variációs Koefficiens): Ez a mutató a teljesítmény időbeli ingadozását számszerűsíti. Azt mutatja meg, hogy a cella mennyire reaktív: képes-e ellenállni a külső, dinamikus környezeti behatásoknak vagy egyes környezeti tényezőkre válaszul összeomlik-e a teljesítménye.
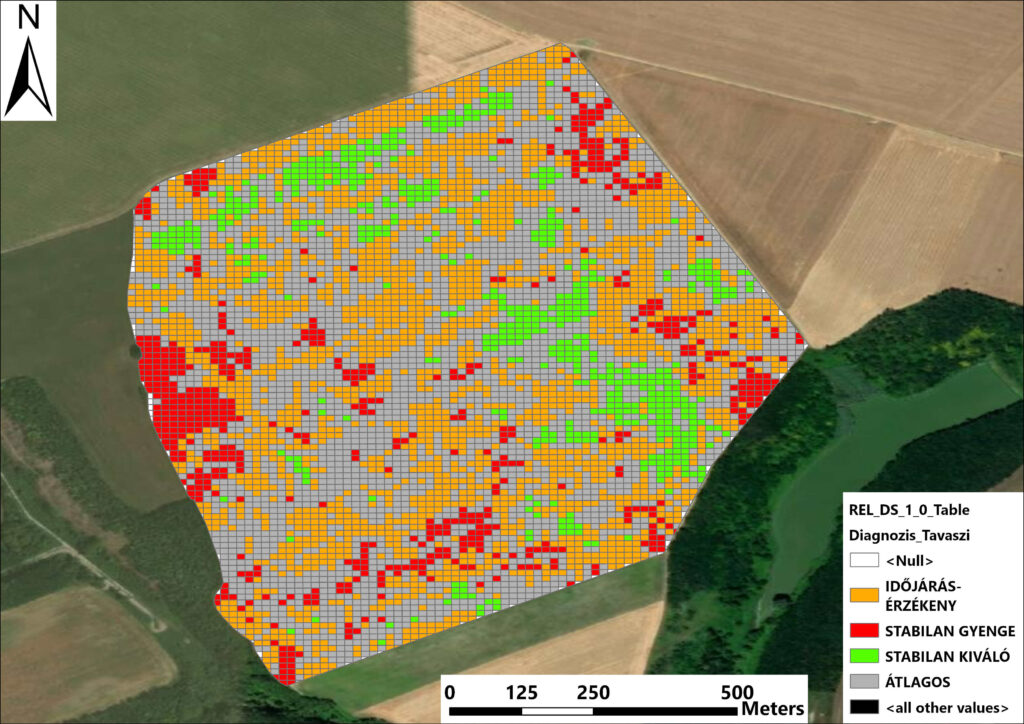
A fenti két paraméter alapján a matematikai modellünk egy diszkriminatív mátrixba rendezte a hálózatot, és négy, funkcionálisan és üzletileg szigorúan elkülönülő kockázati zónára szegmentálta a területet:
- Stabilan kiváló (Magas teljesítmény, alacsony variancia): A rendszer motorja. Ezek a cellák a külső stresszfaktoroktól függetlenül, konzisztensen a maximumot nyújtják. Üzleti szempontból ez a „biztos megtérülési zóna”, ahol a maximális kijuttatási dózisok szükségesek.
- Átlagos (Közepes teljesítmény, alacsony variancia): A rendszer gerincét adó, megbízható alaphálózat. Nincsenek kiugró eredmények, de nincsenek váratlan összeomlások sem.
- Környezeti stresszre érzékeny (Erősen fluktuáló teljesítmény, extrém variancia): A legkritikusabb zóna. Ezek a cellák optimális körülmények között képesek csúcsteljesítményre, de amint egy külső stresszfaktor (pl. aszály, termékenyülés során tartósan magas átlaghőmérséklet) éri őket, a teljesítményük drasztikusan bezuhan. Ide kell fókuszálni a prediktív menedzsmentet és az adaptív beavatkozásokat (pl. differenciált öntözés, műtrágyakijuttatás).
- Stabilan gyenge (Alacsony teljesítmény, alacsony variancia): Rendszerszinten alkalmatlan a profit termelésre. A teljesítménye folyamatosan alacsony, és az ingadozás is minimális, ami azt bizonyítja, hogy a problémát nem külső, időszakos hatások, hanem a talajtani adottságok limitálják. Ezekre a területekre tilos erőforrásokat pazarolni és javításuk sem számít megtérülő befektetésnek.
Térbeli prediktív modellek építésénél a legnagyobb veszély a túltanulás (overfitting) – amikor a modell csupán a múltbeli adatok zaját tanulja meg, de nem képes általánosítani. Ennek kiküszöbölésére, valamint a kockázati profilok térbeli stabilitásának igazolására egy ötszörös keresztvalidációs (5-fold cross-validation) eljárást integráltunk az architektúránkba. Az algoritmus iteratív módon, évenkénti bontásban kizárt bizonyos adattömegeket (teszt-halmaz), míg a maradék éveken (tanító-halmaz) újra lefuttatta a kvadráns-analízist. A kutatás és modellépítés rávilágított arra, hogy a konvencionális, többéves hozamátlagokon alapuló tervezés nem képes kezelni a táblán belüli dinamikus változásokat.
Teljesítményszakadék (performance gap) és célzott ROI optimalizálás
A térbeli adatelemzés végső és legfontosabb mérőszáma nem a puszta statisztikai szórás, hanem a kőkemény üzleti megtérülés (ROI). Tehát hová allokáljuk a forrásainkat, hogy a legnagyobb megtérülést kapjuk? Ennek megválaszolására a pipeline utolsó, prediktív rétegeként bevezettük a Teljesítményszakadék (Performance Gap) mutatót. Ez az algoritmus minden egyes cellánál kvantitatívan számszerűsíti a tényleges, historikus produkció és a cella által valaha bizonyított, elméleti lokális maximum közötti különbséget. Tehát pontosan megmutatja a realizálatlan, „asztalon hagyott” profit mértékét térbeli eloszlásban.
A tesztadatbázisunk futtatása extrém eredményt hozott: a modell pontosan kimutatta, hogy a vizsgált cellák 45,59%-a tartozik a „környezeti stresszre érzékeny” kategóriába, ahol az átlagos teljesítményszakadék őszi kultúrák esetében eléri a 17,84%-ot. Miért kritikus és sorsdöntő ez az adat? Mert a vizsgált táblában átlagosan ennyi elő nem állított termény marad bent, amire a tábla amúgy képes lenne és mert radikálisan átírja a korábban alkalmazott, berögzült stratégiákat.
Megtérülés oldalról nézve az egyes kockázati besorolású cellákat, sokkal jövőbemutatóbb kijuttatástervezés valósítható meg az egyszerűen csak átlagokon alapuló tervezésnél. Azonban ehhez több éves hozamadatsorok szükségesek. Hiszen a mindenkori időjárás függvényében a kockázati mátrix alapján pontosan tudjuk hova és mikor, mennyi inputanyagot érdemes kijuttatni. Ezáltal megvalósul az adatvezérelt, a körülményekhez mérten maximális ROI-val rendelkező gazdaság optimalizálása.
Munkánkat az ISPA (International Society of Precision Agriculture) világszervezet is elismerte és a 2026-os világkonferenciára a poszter szekcióba emelte.
